The rapid convergence of advanced data science and traditional corporate finance has fundamentally transformed the American financial sector. Modern corporate treasuries, institutional investment firms, and banking networks across the United States have largely retired legacy, rule-based accounting practices. In their place stands a complex digital ecosystem driven by quantitative modeling, automated risk assessment, and machine learning pipelines. For undergraduate and graduate students pursuing degrees in financial engineering, corporate governance, and quantitative analytics, this rapid technological shift has completely rewritten the academic playbook.
The modern curriculum no longer permits a surface-level understanding of fiscal balance sheets or basic asset valuation models. Today’s business and engineering schools demand that students possess an intersectional fluency combining advanced mathematical theory, computer science, and corporate strategy. Navigating the steep learning curve of these automated systems presents unprecedented academic hurdles. This analysis breaks down the most difficult operational hurdles within contemporary FinTech systems, examining exactly why advanced students struggle to master these paradigms and how targeted educational frameworks bridge the gap.
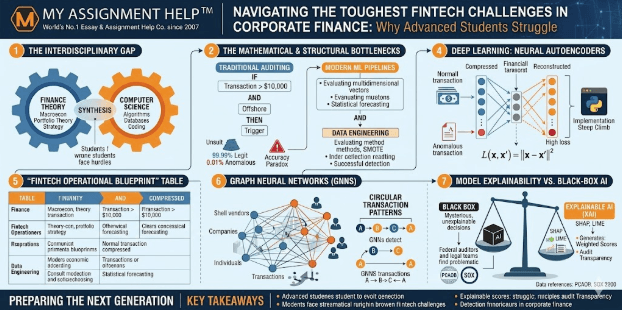
The Interdisciplinary Gap in FinTech Education
The primary reason advanced students face immense hurdles in this field is the sheer breadth of cross-disciplinary knowledge required. Traditional finance curricula historically focused on macroeconomic trends, corporate accounting, and portfolio theory. Conversely, computer science tracks prioritized algorithmic efficiency and database architecture. Modern FinTech operations require a flawless synthesis of both worlds.
When students are tasked with designing or auditing automated compliance platforms, they frequently experience a profound disconnect between theoretical math and practical corporate application. Understanding the theoretical capabilities of an algorithm is meaningless if a student cannot align it with the operational objectives of a live corporate entity. To overcome these academic hurdles, students frequently depend on specialized management assignment help to master corporate governance frameworks, strategic implementation designs, and the systemic change-management methodologies required to integrate automated tools into existing business structures. Without this critical foundational grounding in organizational strategy, even the most brilliant mathematical models fail to function within a real-world corporate hierarchy.
The stakes for mastering these competencies are incredibly high. According to recent industry reports from the Association of Certified Fraud Examiners (ACFE), organizations worldwide lose roughly 5% of their annual revenues to internal and external financial anomalies, with a median loss of 145,000 per infraction before discovery. In the United States, stringent regulatory frameworks like the Sarbanes-Oxley Act (SOX) place immense pressure on corporations to deploy real-time, automated internal controls. As a result, the job market has little patience for half-trained analysts; employers require graduates who can immediately manage high-frequency transactional data streams and spot hidden structural deviations.
The Mathematical and Structural Bottlenecks of Automated Audit Systems
To understand why financial engineering students struggle, one must examine the absolute complexity of the computational models driving modern internal controls. Traditional corporate auditing relied on straightforward, linear logic gates—constructed as rigid, rule-based systems:
\text{IF } (\text{Transaction\_Value} > \10,000) \text{ AND } (\text{Geographic\_Source} == \text{“Offshore”}) \text{ THEN } \text{Trigger\_Flag}
While this Boolean framework is easy to program and simple to understand, it is completely useless against sophisticated, modern financial anomalies. Modern bad actors easily exploit these static boundaries through “micro-streaming”—breaking down a large illicit transaction into thousands of tiny, sequential transfers (e.g., 9,950 each) to systematically bypass standard detection triggers.
To counter this, modern American enterprise systems utilize complex machine learning pipelines that evaluate multidimensional behavioral vectors simultaneously. This shifts the academic burden from simple accounting tracking to highly complex statistical forecasting and predictive anomaly isolation.
1. Class Imbalance and Data Engineering Hurdles
In real-world data science, financial anomalies are incredibly rare. Within a standard corporate ledger containing millions of entries, legitimate operational transactions outnumber fraudulent or anomalous ones by an overwhelming margin—often exceeding 99.99\% to 0.01\%.
When students attempt to train machine learning models on these highly unbalanced datasets, their models almost always suffer from “accuracy paradoxes.” The algorithm simply learns to classify every single transaction as legitimate, achieving a 99.99% accuracy rate while completely failing to catch the critical 0.01% of actual anomalies. To solve this, students must learn to implement highly advanced data engineering techniques, such as Synthetic Minority Over-sampling Technique (SMOTE), or configure cost-sensitive loss functions that heavily penalize missed detections. Mastering these fine data adjustments requires deep statistical intuition that many students struggle to develop under standard classroom constraints.
2. The Hidden Complexities of Neural Autoencoders
For high-frequency transaction streams, modern FinTech architectures rely on unsupervised deep learning models, specifically autoencoders. An autoencoder is designed to compress standard financial data into a lower-dimensional bottleneck layer, and then attempt to reconstruct that exact data perfectly on the other side.
Because the network is trained exclusively on normal corporate transactions, it learns to reconstruct standard ledger entries with near-zero error. However, when an anomalous transaction passes through the system, the autoencoder fails to reconstruct it accurately. The resulting spike in the reconstruction error—calculated via the mathematical loss function:
L(x, x’) = \|x – x’\|^2
instantly triggers a real-time compliance alert.
For students, translating this pure mathematical loss function into a working Python script that can process live enterprise data streams is an incredibly steep uphill climb. Because university curricula often rush through the foundational mathematics of deep learning, aspiring analysts frequently seek comprehensive financial assignment help to master stochastic modeling, matrix operations, and neural network tuning. Gaining a complete grasp of this advanced quantitative machinery is the only way students can successfully design and maintain the automated systems safeguarding multi-million dollar corporate assets.
See also: techelsa
FinTech Operational Blueprint: Student Knowledge Breakdown
[A structured instructional flowchart outlining the step-by-step pipeline from data ingestion to machine learning anomaly classification, emphasizing where students encounter critical learning bottlenecks]
| Technical Domain | Core Analytical Frameworks | Primary Corporate Function | Student Learning Bottleneck |
| Supervised Classifiers | XGBoost, LightGBM, Random Forests | Categorizing historical transaction data; flagging known duplicate billing patterns. | Overfitting models to historical data; inability to handle dynamic zero-day exploits. |
| Unsupervised Clustering | Isolation Forests, DBSCAN Analytics | Discovering entirely new, unclassified behavioral anomalies and network hacks. | Managing extreme data noise; misinterpreting benign operational changes as threats. |
| Deep Learning Architectures | Deep Autoencoders, LSTM Networks | Processing high-volume transaction telemetry and unstructured text data in real time. | Translating complex reconstruction loss formulas into scalable database code. |
| Network Topology & Graphs | Graph Convolutional Networks (GCN) | Mapping complex webs of shell vendors and circular wiring networks. | Visualizing abstract relational data spaces; high computing power requirements. |
Advanced Graph Topologies: Uncovering Collusive Fraud Networks
The challenges deepen when students transition from analyzing isolated transactions to mapping coordinated corporate financial crimes. Modern financial malfeasance rarely involves a single rogue employee or an isolated invoice error. Instead, professional bad actors construct intricate webs of shell companies, dummy vendor accounts, and complex circular wiring loops to obscure the true path of stolen corporate assets.
Traditional SQL-based relational databases fail to catch these patterns because they process financial ledgers row-by-row. To solve this, advanced FinTech operations utilize Graph Neural Networks (GNNs). In this network topology, bank accounts, companies, and physical addresses are treated as nodes, while transactions and communications are mapped as edges.
GNNs look at the entire network structure simultaneously, allowing them to instantly flag circular transaction patterns (e.g., Company A transfers money to Company B, which routes it to Company C, which immediately wires it back to Company A). For financial engineering students, transitioning from flat spreadsheet analysis to three-dimensional graph topology represents a massive conceptual leap that requires advanced spatial reasoning and specialized network data engineering skills.
The Governance Dilemma: Model Explainability vs. Black-Box AI
Even if a student successfully builds an advanced neural network capable of catching anomalies, they run straight into one of the biggest debates in modern US corporate governance: the “Black Box” problem. Deep learning models are incredibly complex, and tracing the exact mathematical path an algorithm took to flag a specific transaction is notoriously difficult.
Under current US financial regulations, including the strict auditing expectations set by the Public Company Accounting Oversight Board (PCAOB), corporate risk managers cannot simply state that “the AI flagged it.” If an automated system freezes a multimillion-dollar vendor payment, compliance officers must be able to explain the exact reasoning to federal auditors, internal boards, or legal teams.
Consequently, students must master Explainable AI (XAI) frameworks, such as SHAP (SHapley Additive exPlanations) or LIME. These mathematical toolkits break down a complex AI decision into clear, weighted scores, showing exactly how much variables like transaction location, execution speed, or user authorization changes contributed to the alert. Learning to balance high-power algorithmic performance with regulatory transparency is a difficult corporate reality that many students find hard to navigate without structured academic support.
Conclusion: Preparing the Next Generation of FinTech Leaders
The digital revolution within corporate finance systems is a permanent shift. As American enterprises continue to automate their financial infrastructures, the demand for highly skilled quantitative analysts who can confidently manage machine learning pipelines, deep learning models, and graph networks will only continue to rise.
For students currently fighting their way through advanced financial engineering programs, the academic journey is undeniably demanding. Success in this field requires moving past simple textbook equations and embracing the messy, complex realities of live enterprise data engineering and strategic corporate compliance. By mastering these highly technical domains, developing a strong analytical mindset, and utilizing target educational resources when academic workloads become overwhelming, the next generation of FinTech professionals can successfully protect corporate assets and drive innovation across the global financial sector.
Key Takeaways for Aspiring FinTech Professionals
- Master the Intersections: True expertise requires a deep understanding of computer science algorithms balanced with a clear grasp of corporate strategy and change management.
- Focus on Data Preparation: Resolving massive class imbalances via sampling methods like SMOTE is just as critical as selecting the final machine learning model.
- Prioritize Transparency: Every algorithmic alert must be fully explainable to corporate compliance boards and federal regulators through tools like SHAP.
- Think in Systems: Shift your analytical perspective from viewing transactions as isolated spreadsheet rows to tracking them as interconnected network graphs.
Frequently Asked Questions (FAQ)
1. Why do traditional rule-based compliance systems fail in modern US corporate environments?
Rule-based systems rely on rigid, static constraints that can only flag known historical patterns. Modern financial anomalies are dynamic and adaptive; bad actors easily bypass static rules using tactics like micro-streaming, which machine learning pipelines detect by looking at broader behavioral anomalies.
2. What is the “accuracy paradox” in financial data modeling, and how can students fix it?
Because legitimate ledger entries vastly outnumber anomalous ones, an algorithm can simply guess that every transaction is safe and achieve 99.99% accuracy while completely missing actual fraud. Students fix this by using synthetic over-sampling techniques (SMOTE) or configuring cost-sensitive loss functions.
3. How do Graph Neural Networks expose hidden networks of financial collusion?
Instead of analyzing ledger rows individually, GNNs view corporate financial data as a connected ecosystem of nodes and edges. This allows compliance systems to track relational flows and instantly flag suspicious patterns like circular wire transfers or hidden partnerships between shell companies.
4. Why are Explainable AI frameworks like SHAP necessary in corporate risk management?
US corporate regulations require complete audit transparency. If an AI platform flags an internal transaction without clear context, the company cannot justify its compliance actions to federal regulators. Frameworks like SHAP break down complex machine learning decisions into clear, auditable risk factors.
About the Author
Dr. Julian Vance, Senior FinTech Research Analyst & Subject Matter Expert
Dr. Julian Vance holds a Ph.D. in Quantitative Finance from a top-tier US business school and specializes in algorithmic internal controls, data engineering, and enterprise risk modeling. Dr. Vance leads advanced content strategy and educational development programs for the academic support team at MyAssignmentHelp. Over the past decade, his research has focused on bridging academic financial theories with real-world enterprise applications, helping future financial leaders master advanced predictive tools and machine learning compliance architectures.
Data Sources & Academic References
- Association of Certified Fraud Examiners (ACFE). (2024). Report to the Nations: Occupational Fraud 2024: A Report to the Nations. ACFE Global Headquarters.
- Sarbanes-Oxley Act of 2002, Pub. L. No. 107-204, 116 Stat. 745 (2002).
- Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems (NeurIPS 2017), 30.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
